La Inteligencia Artificial local en Mac acaba de sumar una herramienta que está llamando mucho la atención entre desarrolladores y usuarios avanzados de Apple Silicon. Se llama oMLX y se presenta como un servidor de inferencia para modelos de lenguaje optimizado para Mac con chip M1, M2, M3 y M4, con una propuesta que mezcla rendimiento, interfaz nativa y compatibilidad con los flujos de trabajo que ya usan muchos agentes de IA para programar. No es el primer proyecto que intenta llevar grandes modelos a macOS, pero sí uno de los que mejor ha entendido un problema muy concreto: usar IA local de forma seria en el día a día no depende solo de que el modelo funcione, sino de que la experiencia de uso deje de ser una pelea constante con la terminal, la memoria y el contexto.
El proyecto está disponible como aplicación para macOS, como instalación vía Homebrew y también desde código fuente. Requiere macOS 15 Sequoia o superior, Python 3.10+ y Apple Silicon, y permite lanzar un servidor local accesible desde clientes compatibles con la API de OpenAI o Anthropic. Además, incluye una app nativa en la barra de menú, un panel de administración web y una descarga integrada de modelos desde Hugging Face, lo que lo aleja bastante de la imagen clásica del servidor LLM local reservado a perfiles muy técnicos.
El gran argumento de oMLX: contexto persistente y menos fricción
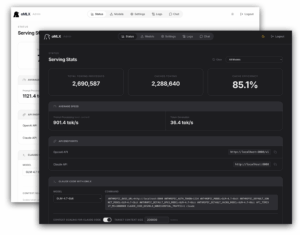
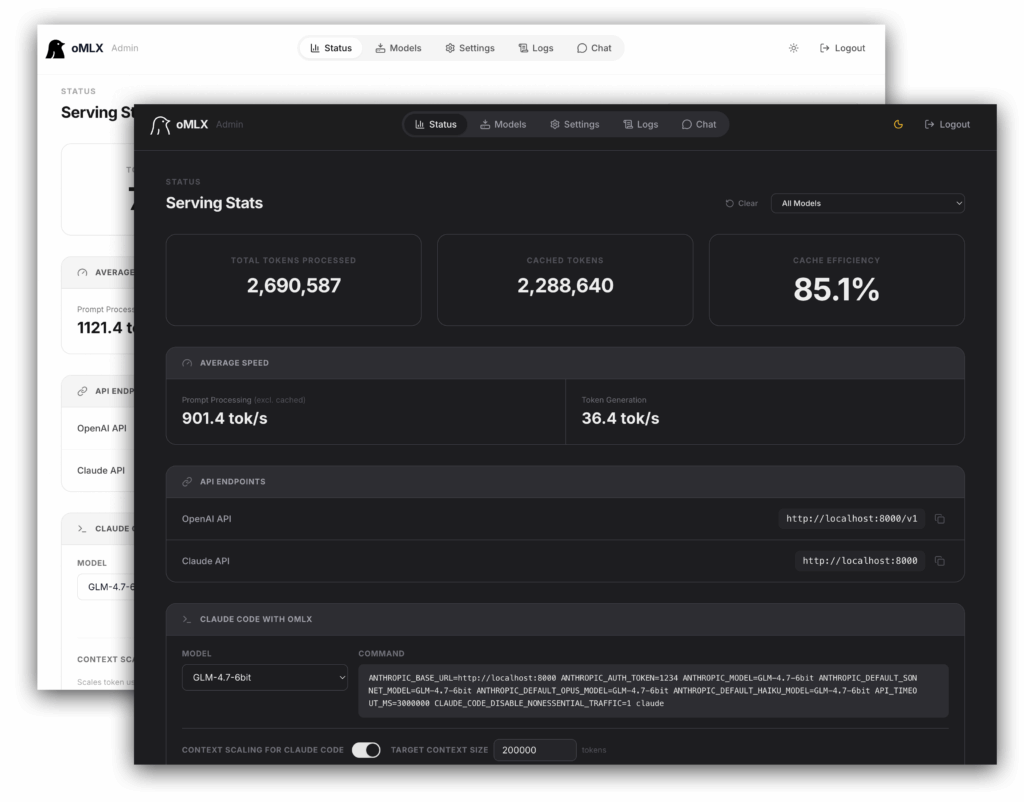
Lo que más diferencia a oMLX de otros servidores locales no es solo la compatibilidad con modelos, sino su enfoque en la gestión del contexto. Su documentación oficial destaca dos pilares: continuous batching y tiered KV cache. El primero permite manejar varias peticiones concurrentes mediante el generador por lotes de mlx-lm, algo importante cuando se usan clientes, agentes o herramientas que lanzan varias llamadas seguidas. El segundo divide la caché KV en dos niveles: una capa caliente en RAM y otra fría en SSD, de forma que el contexto previo puede mantenerse reutilizable incluso cuando no cabe ya en memoria o cuando el servidor se reinicia.
Esa idea tiene bastante sentido para usuarios que programan con agentes de IA en local. En muchos flujos de trabajo reales, el coste no está tanto en generar unas pocas líneas de respuesta, sino en volver a prefijar una y otra vez contextos largos: archivos, instrucciones, historial y cambios de prompt. oMLX intenta evitar parte de ese desperdicio guardando bloques de caché en disco en formato safetensors y recuperándolos después con rapidez cuando el prefijo coincide. Su creador lo plantea como una forma de hacer “prácticos” los LLM locales para trabajo real de programación, especialmente con herramientas como Claude Code. Es una promesa ambiciosa, pero técnicamente bastante alineada con uno de los cuellos de botella más habituales del uso local.
Más que un servidor: app nativa, dashboard y servicio en segundo plano
Otro de los puntos fuertes de oMLX es que no se limita a exponer un puerto local. El proyecto incluye una aplicación nativa para la barra de menú de macOS, construida con PyObjC y no con Electron, algo que probablemente apreciarán quienes prefieren herramientas más ligeras y mejor integradas con el sistema. Desde esa app se puede iniciar, detener y monitorizar el servidor sin abrir Terminal, además de ver estadísticas persistentes y beneficiarse de reinicio automático en caso de caída.
A eso se suma un dashboard web en /admin con funciones bastante amplias: monitorización en tiempo real, gestión de modelos, chat integrado, benchmarks, configuración por modelo, descarga directa de modelos desde Hugging Face y accesos rápidos para integraciones con OpenClaw, OpenCode o Codex. En la práctica, oMLX intenta cubrir tanto al usuario que quiere “hacer clic y usar” como al que prefiere levantarlo como servicio en segundo plano con brew services start omlx y tratarlo como infraestructura local permanente.
También es relevante su compatibilidad con varias familias de modelos. La documentación habla de LLM, VLM, modelos OCR, embeddings y rerankers, todos dentro del mismo servidor. Y en las notas de la última release candidata, publicadas el 14 de abril, el proyecto añade además soporte de audio a través de mlx-audio, con endpoints compatibles para transcripción, síntesis y procesamiento de audio. Eso no convierte automáticamente a oMLX en la solución definitiva para todos los usos, pero sí lo sitúa como una plataforma local bastante más versátil que un simple servidor de chat.
Por qué importa para quienes programan con IA en Mac
La relevancia de oMLX está en que responde a una necesidad muy concreta que hasta ahora seguía mal resuelta en Apple Silicon: disponer de una capa local para agentes de IA que sea rápida, razonablemente cómoda y compatible con herramientas ya pensadas para OpenAI o Anthropic. Su web lo presenta explícitamente como backend “drop-in” para clientes que esperan esos formatos de API, y el servidor expone endpoints como /v1/chat/completions, /v1/completions, /v1/messages, /v1/embeddings y /v1/rerank. Eso facilita bastante su adopción como sustituto local de una API remota en determinados escenarios.
Para muchos desarrolladores, el valor no está solo en la privacidad o en ahorrar llamadas a una API comercial. También está en ganar control: fijar modelos en memoria, limitar TTL por modelo, activar descarga y carga manual, usar compatibilidad con herramientas MCP, ajustar límites de memoria del proceso y decidir hasta qué punto aprovechar SSD para extender el contexto sin agotar la RAM. Todo eso aparece ya en la documentación oficial y dibuja una herramienta pensada por alguien que conoce bien los problemas de usar modelos grandes en un portátil Mac real, no en una demo idealizada.
Aun así, conviene no exagerar. oMLX no elimina las limitaciones físicas de Apple Silicon ni convierte cualquier Mac en un servidor milagroso para modelos gigantes. Su rendimiento dependerá del modelo elegido, del tamaño del contexto, de la memoria disponible y del equilibrio entre velocidad y almacenamiento en caché. Pero sí parece uno de los proyectos más serios que han aparecido últimamente para cerrar la brecha entre “IA local interesante” e “IA local realmente utilizable” en macOS. Y en un momento en el que cada vez más desarrolladores quieren combinar agentes, privacidad, contexto persistente y coste controlado, eso no es poca cosa.
Preguntas frecuentes
¿Qué es oMLX y para qué sirve en un Mac con Apple Silicon?
oMLX es un servidor local de inferencia para LLM y otros modelos en macOS, diseñado para Apple Silicon. Permite servir modelos locales con compatibilidad de API estilo OpenAI y Anthropic, con gestión desde la barra de menú, dashboard web y caché KV en RAM y SSD.
¿Qué requisitos necesita oMLX para funcionar?
Según su documentación oficial, requiere macOS 15.0 o superior, Python 3.10+ y un Mac con chip M1, M2, M3 o M4. La app para macOS se distribuye como .dmg, pero también puede instalarse con Homebrew o desde el código fuente.
¿oMLX es compatible con agentes y clientes que usan la API de OpenAI o Anthropic?
Sí. Expone endpoints compatibles con OpenAI como /v1/chat/completions y también con Anthropic mediante /v1/messages, lo que le permite actuar como backend local para varios clientes y herramientas de desarrollo.
¿Qué aporta la caché KV en SSD de oMLX frente a otros servidores locales?
Permite conservar contexto más allá de la RAM, descargando bloques a SSD y recuperándolos después cuando el prefijo coincide. Eso reduce recomputación en flujos con prompts largos y conversaciones de trabajo repetitivas, especialmente útiles en programación asistida por IA.