Claude Code se ha convertido en una de las herramientas de desarrollo con Inteligencia Artificial más activas del momento, pero una parte importante de su uso seguía siendo bastante opaca para muchos usuarios: cuántos tokens se consumen realmente, qué modelos se están usando en cada sesión, cuánto costaría ese trabajo en la API y cómo evoluciona ese consumo con el tiempo. Ahí es donde entra claude-usage, un proyecto open source publicado en GitHub que convierte los registros locales de Claude Code en un panel de control con historial de sesiones, gráficos y estimaciones de coste.
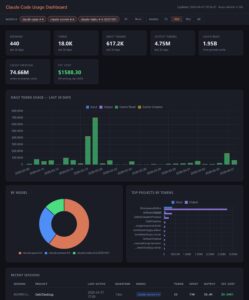
La idea es simple, pero toca una necesidad real. Anthropic ya documenta que ~/.claude almacena datos que Claude Code va escribiendo durante el trabajo, incluidos transcripciones, historial y registros, y su propio SDK explica además que las sesiones se guardan bajo ~/.claude/projects/<encoded-cwd>/*.jsonl. El repositorio de phuryn/claude-usage se apoya precisamente en esos archivos para construir una base SQLite local y servir un panel web en localhost:8080, sin depender de servicios externos ni de enviar datos a terceros.
Una capa de visibilidad que Anthropic todavía no da de serie
Uno de los puntos más interesantes del proyecto es que no inventa una fuente de datos nueva, sino que aprovecha la telemetría local que ya genera Claude Code. Según el README del repositorio, el escáner procesa los ficheros JSONL de sesión, extrae campos como input_tokens, output_tokens, cache_creation_input_tokens, cache_read_input_tokens y el modelo usado, y los guarda en ~/.claude/usage.db. A partir de ahí, el panel muestra resúmenes diarios, estadísticas acumuladas y filtros por modelo.
Eso cubre una carencia que muchos usuarios venían señalando desde hace tiempo. La propia documentación oficial de Claude Code sí ofrece mecanismos como la status line personalizable, capaz de mostrar uso de contexto o costes en una barra inferior, pero no proporciona de serie un tablero histórico con sesiones, consumo agregado y estimaciones económicas persistentes. En ese hueco es donde encaja bien una herramienta como claude-usage: no sustituye a Claude Code, pero sí añade una capa de observabilidad que para perfiles intensivos puede resultar muy útil.
Cómo funciona y por qué resulta atractivo para desarrolladores
El proyecto está diseñado para ser deliberadamente ligero. Su autor explica que solo necesita Python 3.8 o superior y que no usa dependencias de terceros: se apoya en la biblioteca estándar, con módulos como sqlite3, http.server, json y pathlib. En un ecosistema donde muchas utilidades terminan pidiendo pip, entornos virtuales, compilación de frontend o varias dependencias JavaScript, esa sencillez puede ser una ventaja importante para quien solo quiere inspeccionar su uso sin complicarse.
La operativa también es bastante directa. El proyecto propone cuatro comandos básicos: scan para indexar los archivos JSONL, today para ver el uso del día en terminal, stats para consultar datos acumulados y dashboard para lanzar el panel web. Además, el escaneo es incremental: el propio README indica que rastrea ruta y fecha de modificación de cada archivo para reprocesar solo lo nuevo o lo cambiado, lo que evita tener que releer todo el historial cada vez.
En términos de experiencia, el valor real no está solo en ver números, sino en entender mejor los patrones de trabajo con Claude Code. Qué modelos se usan más, cuánto pesan las lecturas de caché, qué sesiones se disparan de tamaño o qué proyecto consume más contexto son preguntas que empiezan a importar mucho cuando el uso deja de ser ocasional y pasa a convertirse en una herramienta diaria de desarrollo. Claude Code, además, sigue evolucionando rápido —su changelog oficial ya va por la versión 2.1.94 el 7 de abril de 2026—, así que tener una visión local del uso ayuda también a detectar cambios de comportamiento entre versiones.
No todo lo que hace Claude Code queda reflejado igual
Dicho eso, el propio proyecto también deja claras sus limitaciones, y conviene subrayarlas porque son importantes. El dashboard captura el uso de la CLI de Claude Code, la extensión de VS Code y las sesiones despachadas a través de Claude Code, pero no recoge las llamadas Cowork que se ejecutan del lado del servidor y no escriben transcripciones JSONL locales. Es decir, el panel da una imagen amplia, pero no necesariamente completa de todo el universo Claude.
Además, hay un segundo matiz técnico relevante: los registros locales no siempre son perfectos. En el repositorio público de Claude Code existen incidencias abiertas y cerradas relacionadas con los JSONL, como subcuentas en los output_tokens, discrepancias en el campo del modelo registrado o sesiones remotas que no terminan persistiendo igual en el log local. Eso no invalida una herramienta como claude-usage, pero sí obliga a interpretarla como una aproximación útil y no como una contabilidad forense exacta al céntimo o al token.
También hay que leer con cuidado la parte de los costes. El repositorio calcula estimaciones usando precios de la API de Anthropic y aclara expresamente que, si el usuario trabaja con planes Pro o Max, su estructura real de coste es distinta porque se basa en suscripción y no en facturación directa por token. Ese matiz es clave para no confundir “valor económico equivalente” con “importe que realmente pagará el usuario”. Además, algunos precios mostrados en el README parecen quedar desalineados con las referencias oficiales actuales de Anthropic, que para Sonnet 4.6 siguen indicando 3 dólares por millón de tokens de entrada y 15 dólares por millón de salida, y para Opus 4.6 arrancan en 5 y 25 dólares, respectivamente.
Un síntoma de madurez en el ecosistema Claude Code
Más allá del proyecto concreto, la aparición de herramientas como claude-usage dice algo importante sobre el momento que vive Claude Code. Cuando una plataforma empieza a generar dashboards, navegadores de sesiones, monitores de límites o visores de transcripciones creados por terceros, suele significar que ha dejado de ser una curiosidad para convertirse en una infraestructura de trabajo diaria. No es casualidad que ya existan otros proyectos paralelos para explorar transcripciones o vigilar consumo en menús de macOS. El ecosistema está empezando a construir sus propios instrumentos de control alrededor del producto principal.
En ese sentido, claude-usage no parece una simple utilidad menor, sino una pieza lógica en la profesionalización del uso de agentes de desarrollo. Si Claude Code va a ser parte del flujo normal de trabajo, los equipos van a pedir algo más que buenos resultados: querrán trazabilidad, métricas, costes aproximados y una forma de entender qué está pasando sesión a sesión. Y cuanto más aumente ese uso, más valor tendrá cualquier herramienta capaz de convertir ficheros dispersos en una visión clara del conjunto.
Preguntas frecuentes
¿Qué es exactamente claude-usage?
Es una herramienta open source que lee los registros locales de Claude Code y los convierte en un panel con uso de tokens, historial de sesiones, modelos empleados y estimaciones de coste. Funciona en local y usa SQLite para almacenar los datos procesados.
¿Necesita enviar datos a un servidor externo?
No. El proyecto está planteado como un dashboard local que procesa archivos JSONL ya presentes en ~/.claude/projects/ y sirve la interfaz en localhost:8080.
¿Los costes que muestra son lo que paga un usuario Pro o Max?
No necesariamente. El propio repositorio aclara que usa precios de la API para estimar consumo, mientras que Pro y Max funcionan con un modelo de suscripción distinto. Por tanto, la cifra debe leerse como referencia económica aproximada, no como factura real.
¿Registra toda la actividad de Claude Code sin excepciones?
No del todo. El proyecto indica que no captura las sesiones de Cowork que se ejecutan del lado del servidor. Además, en la documentación y en incidencias públicas de Claude Code ya se han señalado algunas limitaciones y errores en la persistencia o exactitud de ciertos campos de los JSONL.