Anthropic no ha publicado la arquitectura interna de Claude Mythos Preview. Lo que sí ha confirmado es que se trata de su modelo más potente hasta la fecha, que su acceso sigue restringido a una vista previa de investigación y que su despliegue inicial está muy ligado a Project Glasswing, el programa con el que la compañía quiere reforzar la seguridad de software crítico. En otras palabras, Mythos existe, ya se está usando en entornos reales muy acotados, pero su diseño sigue siendo opaco.
Ahí entra OpenMythos. El repositorio de Kye Gomez no afirma haber filtrado ni reproducido el modelo de Anthropic, sino proponer una “reconstrucción teórica” basada en literatura pública y en una hipótesis concreta: que Mythos podría pertenecer a la familia de los Recurrent-Depth Transformers, también llamados looped transformers. El proyecto está implementado en PyTorch, se distribuye como código abierto y se presenta expresamente como un esfuerzo independiente, no afiliado a Anthropic.
Para un medio de programación y administración de sistemas, lo interesante no es el componente especulativo del nombre, sino lo que OpenMythos permite estudiar: una arquitectura donde la profundidad de razonamiento no depende solo de apilar más capas, sino de reutilizar un mismo bloque varias veces dentro de una única pasada de inferencia. Eso desplaza el debate desde “cuántos parámetros almacena el modelo” hacia “cuánto cómputo efectivo consume por petición y cómo escala ese cómputo en tiempo de ejecución”.
Qué implementa realmente OpenMythos
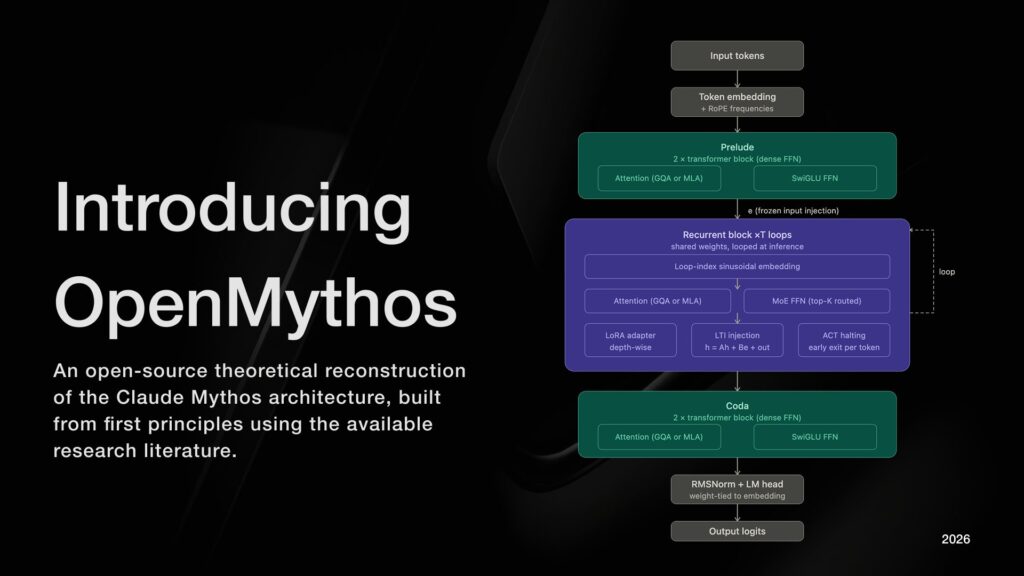
Según su README, OpenMythos estructura el modelo en tres fases: un Prelude con capas transformer convencionales, un bloque recurrente que se ejecuta varias veces y una Coda final. El núcleo está en ese bloque recurrente compartido, donde el estado oculto se actualiza iterativamente con la regla ht+1=A⋅ht+B⋅e+Transformer(ht,e). El repositorio permite conmutar entre MLA y GQA para atención, usa una FFN basada en sparse MoE con expertos enrutados y expertos compartidos, y añade adaptadores LoRA por profundidad para diferenciar ligeramente el comportamiento en cada iteración.
Eso significa que, en términos prácticos, el proyecto mezcla varias ideas recientes de arquitectura: reutilización de pesos, razonamiento implícito en espacio latente, MoE para ampliar capacidad sin activar todo el modelo a la vez, y LoRA depth-wise para evitar que todas las vueltas del bucle hagan exactamente lo mismo. Además, OpenMythos expone configuraciones predefinidas desde 1B hasta 1T de parámetros teóricos, con variantes que aumentan dimensión, número de expertos, contexto y número máximo de iteraciones.
Desde el punto de vista operativo, esto introduce una diferencia importante respecto a un transformer denso clásico. En un modelo fijo, la profundidad computacional está cerrada por la arquitectura. En un looped transformer, una parte de la calidad puede moverse a inferencia: más vueltas implican más FLOPs por petición, pero no obligan a almacenar capas completamente nuevas. Para un desarrollador de inferencia o un administrador de sistemas, eso cambia la manera de pensar el equilibrio entre memoria, latencia y throughput.
Por qué esta idea está ganando tracción en investigación
OpenMythos no sale de la nada. Llega en un momento en el que varios trabajos recientes están empujando justo esta dirección. Loop, Think, & Generalize sostiene que los recurrent-depth transformers pueden mejorar en generalización sistemática y en extrapolación de profundidad, es decir, resolver composiciones nuevas y beneficiarse de más razonamiento implícito dentro de una sola pasada. Parcae, por su parte, aborda uno de los mayores problemas históricos de estas arquitecturas: la inestabilidad del entrenamiento, proponiendo una parametrización estable de la inyección recurrente con control de radio espectral.
La consecuencia es relevante. Si esa línea de trabajo aguanta en modelos grandes, la profundidad deja de ser solo una función del número de capas entrenadas y pasa a depender también del cómputo en inferencia. Parcae afirma, por ejemplo, que una arquitectura looped estable puede mejorar la perplexity frente a diseños looped previos y que, con presupuesto fijo de FLOPs, looping y datos deberían escalarse conjuntamente. Es una forma distinta de mirar el escalado: menos obsesión por crecer en parámetros brutos y más atención a cómo se reutiliza el mismo bloque bajo demanda.

En paralelo, Relaxed Recursive Transformers aporta otra pieza que OpenMythos incorpora de forma explícita: los módulos LoRA por profundidad. La idea es simple y potente. Se comparten los pesos gruesos entre iteraciones, pero se añade una adaptación ligera por vuelta para evitar que el modelo quede demasiado rígido. Ese paper muestra que esta relajación del weight tying puede recuperar gran parte del rendimiento del modelo original, al tiempo que habilita conceptos como continuous depth-wise batching y early exiting.
Qué implica para desarrolladores y administradores de sistemas
Para quien despliega modelos, OpenMythos es interesante porque convierte cuestiones teóricas en problemas muy concretos de infraestructura. La primera es la latencia: si el razonamiento mejora aumentando el número de loops, la calidad ya no depende solo del checkpoint sino también del presupuesto de inferencia por petición. Eso obliga a exponer nuevas palancas en serving: n_loops, políticas de early exit, perfiles por tipo de tarea y límites de coste por usuario o por endpoint. El propio repositorio ya deja ver esa lógica al separar max_loop_iters de n_loops en ejecución.
La segunda es la planificación de memoria. Un diseño con pesos compartidos reduce presión sobre VRAM frente a apilar capas completamente distintas, pero a cambio puede aumentar el tiempo de permanencia de una petición en GPU si se sube la profundidad de inferencia. Si además se combina con MoE, el problema pasa a ser mixto: no solo importan los parámetros totales, sino el patrón de activación por token, la fragmentación de expertos y el comportamiento del router. En esa parte, OpenMythos se inspira claramente en DeepSeekMoE, cuyo paper defiende expertos finamente segmentados y expertos compartidos para mejorar especialización con menor coste computacional que otras MoE más toscas.
La tercera implicación afecta a observabilidad y debugging. Un modelo looped añade un eje de complejidad que no existe en una red de profundidad fija: hay que inspeccionar no solo capas y tokens, sino también iteraciones. Eso abre la puerta a métricas nuevas para producción: distribución real de loops ejecutados, convergencia por posición, saturación del mecanismo de parada, ratio de activación de expertos y estabilidad del estado recurrente. Para un equipo de MLOps o de plataforma, eso significa dashboards distintos, nuevos puntos de fallo y otra forma de correlacionar calidad con coste.
El límite: OpenMythos no demuestra qué es Mythos
Conviene no perder de vista el matiz principal. OpenMythos no prueba la arquitectura de Claude Mythos Preview. Prueba que una combinación concreta de ideas —RDT, MoE, atención tipo MLA/GQA, inyección recurrente estable, LoRA depth-wise— es hoy lo bastante plausible y lo bastante interesante como para merecer una implementación abierta. Anthropic ha confirmado el modelo, su system card y su uso restringido en seguridad ofensiva y defensiva, pero no ha confirmado que el corazón técnico sea este.
Aun así, para desarrolladores y sysadmins, el valor del proyecto está claro. OpenMythos sirve como banco de pruebas para entender por qué la próxima generación de LLM puede dejar de escalar solo en anchura y empezar a hacerlo también en profundidad reutilizable. Si esa tesis se consolida, el trabajo ya no consistirá solo en alojar modelos más grandes, sino en orquestar modelos más adaptativos, con presupuesto de cómputo variable por petición. Y ese es un problema mucho más cercano a sistemas, scheduling y serving que a simple acumulación de parámetros.
Preguntas frecuentes
¿OpenMythos es una implementación real filtrada de Claude Mythos?
No. El repositorio se presenta como una reconstrucción teórica e independiente basada en literatura pública y especulación razonada, sin afiliación con Anthropic.
¿Qué ventaja técnica tiene un recurrent-depth transformer frente a un transformer clásico?
La idea es reutilizar un mismo bloque varias veces por pasada, desplazando parte del escalado hacia el cómputo en inferencia y no solo hacia el número de capas o parámetros almacenados. Papers recientes reportan mejoras en generalización composicional y en eficiencia de escalado para este tipo de diseños.
¿Qué problemas operativos introduce una arquitectura en bucle?
Principalmente latencia variable, necesidad de mecanismos de parada temprana, observabilidad por iteración y una relación más compleja entre coste de inferencia, calidad y throughput. Si además se combina con MoE, también añade complejidad en routing y activación de expertos.
¿Anthropic ha explicado cómo funciona internamente Claude Mythos Preview?
No. Anthropic ha publicado una system card y ha descrito el modelo como su frontier model más capaz, pero no ha hecho pública la arquitectura interna detallada.
Fuente: Openmythos







