El OCR moderno ha mejorado mucho en precisión, pero sigue teniendo un problema incómodo cuando se enfrenta a documentos largos. Muchos sistemas dividen el PDF en páginas, procesan cada imagen por separado, reconstruyen el texto, intentan respetar tablas, títulos, notas, columnas y orden de lectura, y después entregan ese resultado a una base vectorial o a un sistema RAG. Funciona, pero cada salto entre páginas introduce posibilidades de error.
Baidu quiere atacar ese cuello de botella con Unlimited-OCR, un nuevo modelo abierto de reconocimiento y análisis documental pensado para lo que sus autores llaman “one-shot long-horizon parsing”: procesar documentos multipágina en una sola pasada, reduciendo la necesidad de trocear, coser y corregir manualmente la salida. El proyecto se ha publicado en GitHub y Hugging Face bajo licencia MIT, con pesos disponibles y código de inferencia para Transformers y SGLang.
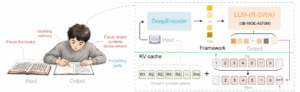
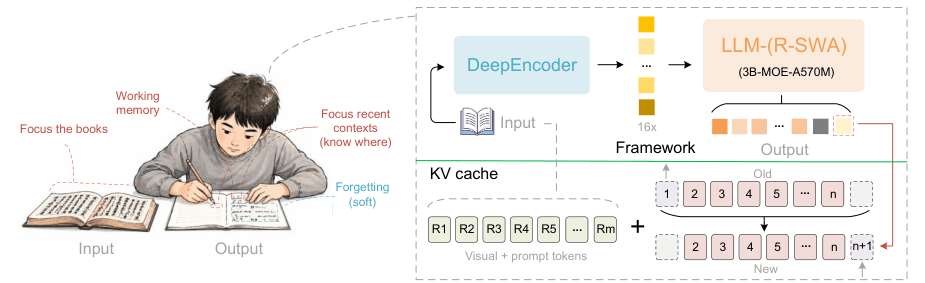
La idea de fondo es sencilla de explicar, aunque técnicamente exigente: mantener el documento visible para el modelo, pero impedir que la memoria de generación crezca sin control a medida que se produce más texto. En un OCR convencional basado en modelos de lenguaje, cuanto más larga es la salida, más crece la caché KV y más memoria consume el sistema. Unlimited-OCR introduce Reference Sliding Window Attention, o R-SWA, para conservar una memoria constante durante la decodificación.
El problema de partir PDFs página a página
La mayoría de flujos documentales empresariales siguen una receta conocida. Primero se convierte cada página del PDF en una imagen, después se ejecuta OCR o parsing página a página, luego se reconstruye el documento completo y finalmente se generan chunks para búsqueda semántica, RAG o análisis con modelos de lenguaje.
Ese proceso tiene varios puntos débiles. Si una tabla continúa entre páginas, si una nota al pie depende de una sección anterior, si un documento tiene dos columnas o si un gráfico se explica en la página siguiente, el sistema puede perder contexto. En contratos, informes financieros, expedientes administrativos, manuales técnicos o documentación científica, esa pérdida de continuidad se nota.
Unlimited-OCR no elimina todos esos retos, pero intenta cambiar la unidad de trabajo. En lugar de tratar cada página como una pieza aislada, permite que el modelo procese varias páginas como parte de una misma tarea de parsing. Esto puede reducir errores de reconstrucción y mejorar la coherencia del texto extraído cuando el documento tiene estructura compleja.
El propio repositorio mantiene una conversión previa de PDF a imágenes mediante PyMuPDF. Es decir, no estamos ante un lector mágico que abra cualquier PDF sin procesamiento intermedio. La diferencia importante está en que esas páginas convertidas a imagen se entregan juntas al modelo para una inferencia multipágina, en lugar de forzar un ciclo independiente por página.
| Enfoque | Cómo trabaja | Riesgo principal |
|---|---|---|
| OCR clásico por página | Procesa cada página por separado | Pierde contexto entre páginas |
| Pipeline OCR + RAG | Extrae, reconstruye, fragmenta e indexa | Errores acumulados en el cosido del documento |
| VLM con salida larga estándar | Mantiene contexto, pero la memoria crece con la salida | Coste y latencia aumentan con documentos largos |
| Unlimited-OCR | Mantiene referencias visuales y usa ventana deslizante de texto generado | Sigue limitado por contexto y calidad visual de entrada |
Qué aporta R-SWA
La aportación técnica principal de Unlimited-OCR es Reference Sliding Window Attention. El mecanismo separa la atención del modelo en dos partes. Por un lado, mantiene acceso a los tokens de referencia, que en este caso son los tokens visuales del documento. Por otro, conserva solo una ventana reciente de tokens generados, en lugar de cargar toda la salida anterior de forma indefinida.
Esto permite que la caché KV permanezca constante durante la decodificación. El modelo no tiene que “recordar” cada palabra ya emitida con el mismo coste creciente que tendría una atención completa. Para tareas de copia, transcripción o parsing, esa restricción es razonable: el modelo necesita saber dónde está, mantener continuidad y no repetir contenido, pero no siempre necesita atender a cada token generado desde el principio.
La consecuencia práctica es que el rendimiento se degrada menos cuando aumenta la longitud de salida. En el informe técnico, Baidu compara Unlimited-OCR con DeepSeek-OCR y muestra que, en escenarios largos, el nuevo mecanismo mantiene mejor la velocidad de generación. En pruebas teóricas de salida larga, la ventaja aumenta a medida que crece el número de tokens.
El modelo parte de DeepSeek-OCR como referencia y conserva su codificador visual de alta compresión. La arquitectura es de tipo MoE, con 3.000 millones de parámetros totales y 500 millones activos, lo que ayuda a contener el coste de inferencia. Baidu afirma que Unlimited-OCR alcanza un 93,23 % en OmniDocBench v1.5 y un 93,92 % en OmniDocBench v1.6, con mejoras frente a la línea base DeepSeek-OCR en edición de texto, fórmulas, tablas y orden de lectura.
Por qué importa para RAG y archivos corporativos
El impacto más interesante no está solo en “hacer OCR más rápido”. Está en mejorar la calidad del texto que alimenta sistemas de búsqueda, clasificación documental, agentes y RAG. Si el documento se rompe mal antes de entrar en el índice, todo lo que ocurre después hereda ese error. Un RAG con chunks limpios, orden de lectura correcto y continuidad entre páginas tiene muchas más opciones de responder bien.
Esto es especialmente importante en empresas con grandes fondos documentales: contratos escaneados, informes regulatorios, documentación técnica, manuales de producto, expedientes, facturas, presentaciones, documentos legales, archivos históricos o PDFs científicos. En muchos de esos casos, el valor no está solo en reconocer palabras, sino en preservar estructura.
El OCR de una factura sencilla o una página escaneada ya está bastante resuelto. El problema difícil es otro: documentos largos, densos, con tablas, fórmulas, cabeceras, notas, columnas, pies, gráficos y referencias cruzadas. Ahí es donde los pipelines clásicos empiezan a acumular parches.
Para equipos que construyen sistemas documentales con IA, Unlimited-OCR apunta a una arquitectura más limpia: menos reconstrucción manual, menos lógica de cosido entre páginas, menos dependencia de reglas externas y más parsing end-to-end. Esto no sustituye la validación, ni elimina la necesidad de comprobar resultados en dominios críticos, pero sí puede reducir una parte pesada del trabajo previo.
Una herramienta abierta, pero todavía técnica
Unlimited-OCR no está pensado para un usuario final que quiera arrastrar un PDF a una interfaz sencilla y olvidarse. Es una herramienta de investigación y despliegue técnico. El repositorio incluye ejemplos para inferencia con Hugging Face Transformers en GPUs NVIDIA, con dependencias probadas sobre Python 3.12.3 y CUDA 12.9. También ofrece una ruta con SGLang para servir el modelo mediante una API compatible con OpenAI.
La inferencia multipágina usa un modo base con imagen a 1.024 píxeles. Para PDFs, el ejemplo convierte cada página en PNG a 300 dpi y después llama a infer_multi. También se incluyen opciones para procesamiento por lotes desde un directorio de imágenes o desde un PDF.
Esto abre la puerta a integrarlo en flujos internos, pero exige criterio técnico. Cargar modelos con trust_remote_code=True, servir endpoints internos, procesar documentos sensibles o indexar salidas para RAG requiere controles de seguridad, aislamiento, revisión de dependencias y pruebas de calidad. La licencia MIT facilita experimentación y adopción, pero no convierte automáticamente el modelo en una solución empresarial cerrada.
| Aspecto | Detalle relevante |
| Desarrollador | Baidu Inc. |
| Modelo | Unlimited-OCR |
| Tipo | OCR y parsing documental end-to-end con visión-lenguaje |
| Tamaño | 3B-A0.5B |
| Técnica principal | Reference Sliding Window Attention |
| Contexto de inferencia | 32K en ejemplos publicados |
| Entrada PDF | Conversión previa a imágenes con PyMuPDF |
| Ejecución | Transformers y SGLang |
| Licencia | MIT |
| Casos de uso | PDFs largos, RAG, archivos corporativos, documentos técnicos |
No es realmente “ilimitado”
El nombre puede llevar a una lectura exagerada. Unlimited-OCR no permite procesar cualquier documento de longitud arbitraria sin límites. Los propios autores reconocen que no puede lograr un parsing verdaderamente ilimitado con una ventana finita como 32K, porque la longitud de prefill también crece a medida que se acumulan páginas. Su plan a corto plazo pasa por entrenar modelos con contextos más largos, como 128K, para admitir más páginas en la entrada.
También hay límites prácticos. En documentos de más de 40 páginas, el informe mantiene resultados razonables, pero señala que los errores repetidos suelen aparecer cuando el texto pequeño del PDF es difícil de discernir, especialmente por la resolución del modo base en escenarios multipágina. Esto recuerda una regla básica del OCR: si la imagen de entrada no contiene suficiente información visual, el modelo no puede inventar una lectura fiable.
La propuesta, aun así, es relevante porque cambia la dirección del problema. Durante años se ha aceptado que el procesamiento documental largo debía dividirse en muchas operaciones pequeñas. Unlimited-OCR plantea que, con una memoria de trabajo mejor diseñada, el modelo puede mantener continuidad durante más tiempo sin que el coste de generación se dispare.
La lectura para empresas es clara. El cuello de botella de la IA documental no está solo en el modelo que responde preguntas, sino en la calidad del texto que recibe. Si los PDFs se fragmentan mal, si se pierden tablas o si el orden de lectura se rompe, el sistema final falla aunque use un buen LLM. Mejorar el OCR largo puede parecer una mejora de infraestructura, pero afecta directamente a la precisión de los asistentes, buscadores internos y agentes corporativos.
Unlimited-OCR llega en un momento en el que la IA empresarial empieza a mirar menos a las demos y más a la operación real. Leer miles de documentos, sostener contexto y entregar texto estructurado no es una función vistosa, pero es una de las bases de cualquier sistema útil. Baidu ha puesto sobre la mesa una solución abierta que habrá que probar fuera del paper, con documentos difíciles y cargas reales, pero su enfoque apunta a uno de los problemas más persistentes del RAG: antes de razonar sobre el conocimiento, hay que extraerlo bien.
Preguntas frecuentes
¿Qué es Unlimited-OCR?
Unlimited-OCR es un modelo abierto de Baidu para OCR y parsing documental de largo contexto. Está pensado para procesar documentos multipágina en una sola tarea, reduciendo la necesidad de reconstruir PDFs página a página.
¿Qué diferencia aporta frente a un OCR tradicional?
La diferencia está en su mecanismo R-SWA, que mantiene acceso a los tokens visuales del documento y solo conserva una ventana deslizante de texto generado. Así evita que la memoria crezca indefinidamente durante salidas largas.
¿Sirve para sistemas RAG?
Sí, puede ser útil como capa previa a RAG porque mejora la extracción y continuidad del texto en documentos largos. Un índice RAG depende mucho de la calidad del parsing inicial.
¿Es realmente ilimitado?
No en sentido literal. El modelo sigue limitado por el contexto disponible, como los 32K tokens de los ejemplos publicados, y por la calidad visual de las páginas. El nombre refleja la intención de reducir el coste creciente de la generación larga, no una ausencia total de límites.