En un movimiento estratégico para abordar las crecientes necesidades de personalización en el campo del aprendizaje automático, Amazon Web Services (AWS) ha introducido soluciones avanzadas que buscan optimizar el desarrollo y la gestión de modelos personalizados. Las organizaciones que dependen de modelos de aprendizaje automático, como las empresas de atención médica e instituciones financieras, enfrentan desafíos únicos que requieren configuraciones específicas de hardware y software.
Estas demandas han impulsado a las empresas a crear entornos de entrenamiento a medida, una tarea que, aunque esencial, presenta complejidades significativas. Construir y gestionar estos entornos personalizados implica altos costos operativos y un gran esfuerzo por parte del equipo de ingeniería, especialmente cuando se recurren a herramientas personalizadas o soluciones de código abierto.
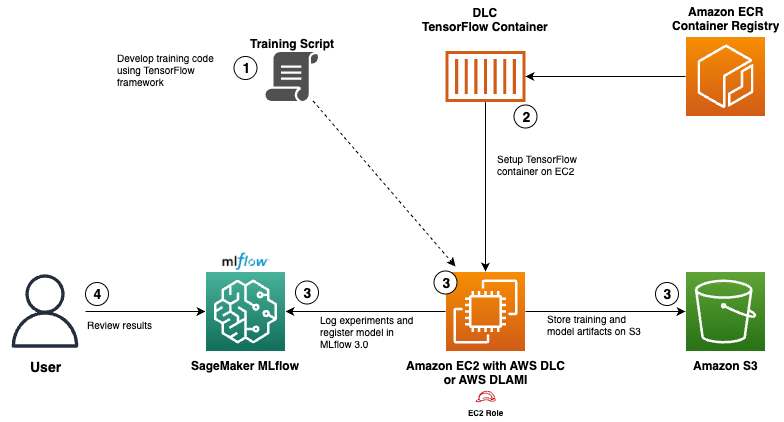
Con el objetivo de simplificar este proceso, AWS ha lanzado herramientas como los «Deep Learning Containers» (DLC) y el servicio gestionado MLflow a través de Amazon SageMaker AI. Los DLC son contenedores de Docker preconfigurados, que incluyen frameworks como TensorFlow y PyTorch, además de controladores NVIDIA CUDA para ofrecer soporte de GPU. Estos contenedores están diseñados para funcionar de manera óptima en AWS, asegurando actualizaciones constantes y una integración fluida con los servicios de la nube de Amazon para operaciones de entrenamiento e inferencia.
Adicionalmente, AWS ha potenciado la gestión del ciclo de vida del ML mediante MLflow gestionado, que facilita el registro automático de experimentos, mejora la comparación de modelos y permite el seguimiento detallado de la procedencia. Este servicio, completamente gestionado, aligera considerablemente la carga operativa de mantener la infraestructura necesaria.
La conjunción de los DLC con el MLflow gestionado ofrece a las organizaciones no solo el control sobre su infraestructura, sino también una gobernanza robusta sobre el aprendizaje automático. Esta combinación reduce el tiempo y los recursos necesarios para gestionar el ciclo de vida del ML, a la vez que permite adaptar las soluciones a necesidades específicas.
Un ejemplo ilustrativo de esta implementación es el desarrollo de un modelo de red neuronal en TensorFlow diseñado para predecir la edad de abalones. Este modelo se beneficia de un contenedor de entrenamiento optimizado tomado del repositorio público de ECR de AWS, que se ejecuta en una instancia EC2 con acceso al servidor de seguimiento de MLflow. El caprichoso proceso involucra almacenar artefactos en Amazon S3 y registrar resultados del experimento, lo que finalmente lleva a una comparación de modelos a través de la interfaz de usuario de MLflow.
El proceso completo culmina con el registro del modelo en el «Modelo Registry de Amazon SageMaker», asegurando una auditoría completa desde la fase experimental hasta el despliegue del modelo en producción. Esta estrategia no solo maximiza la eficiencia y la eficiencia de la gestión de modelos, sino que también facilita una gobernanza más sólida, manteniendo al mismo tiempo la flexibilidad necesaria para seguir innovando en el dinámico mundo del aprendizaje automático.








