El auge del RAG ha traído una paradoja incómoda para el mundo de la inteligencia artificial: cuanto más útil resulta buscar conocimiento sobre documentos, correos, chats, código o historial personal, más pesado se vuelve el sistema que hace posible esa búsqueda. Las bases de datos vectoriales tradicionales suelen exigir un coste de almacenamiento tan alto que, en muchos casos, ejecutar un RAG serio en un portátil o en un equipo personal deja de ser práctico. Ahí es donde quiere entrar LEANN, un proyecto open source que promete recortar de forma drástica ese coste sin hundir la calidad de recuperación.
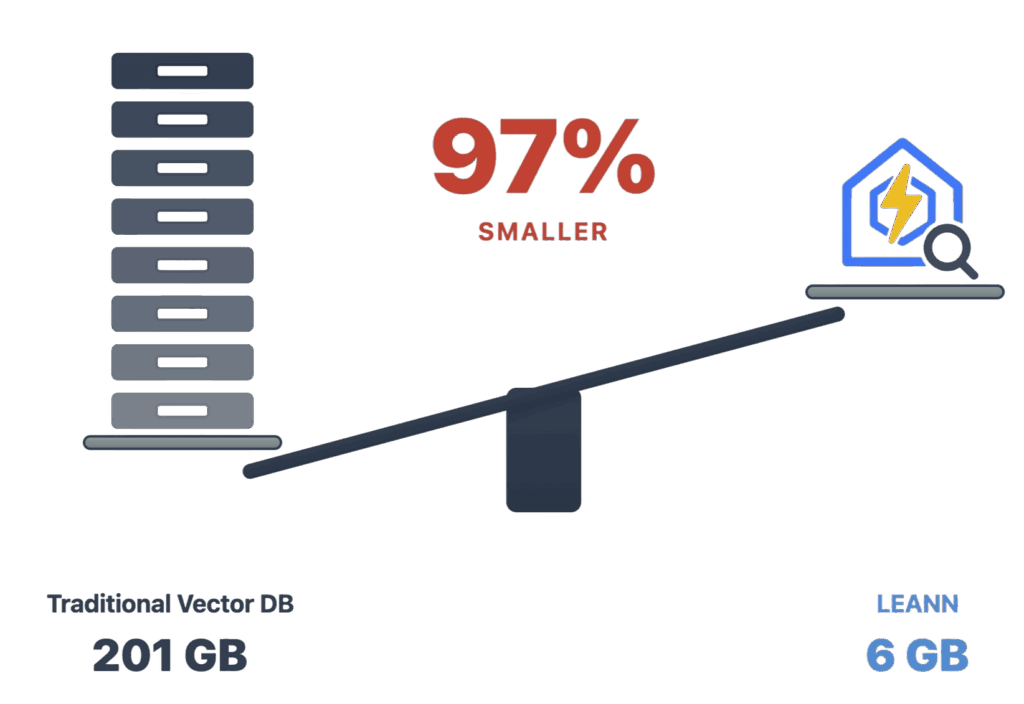
La cifra que ha convertido a LEANN en uno de los repositorios más comentados del momento es muy concreta: en su tabla comparativa, el proyecto afirma que un índice sobre 60 millones de fragmentos de texto que ocuparía 201 GB en una base vectorial tradicional puede quedarse en 6 GB con LEANN, lo que supone un ahorro aproximado del 97 %. El mismo patrón se repite en otros casos que publica el repositorio: de 1,8 GB a 64 MB en chats, de 2,4 GB a 79 MB en correo y de 130 MB a 6,4 MB en historial de navegador.
La propuesta no sale de la nada. Detrás está el trabajo académico “LEANN: A Low-Storage Vector Index”, firmado por investigadores vinculados a UC Berkeley y otros colaboradores, donde se plantea una idea relativamente simple de explicar, aunque sofisticada en su ejecución: en lugar de almacenar todos los embeddings como hacen muchas soluciones convencionales, LEANN guarda una estructura de grafo mucho más compacta y recalcula embeddings bajo demanda durante la búsqueda. Según el paper, esa estrategia permite reducir el almacenamiento a menos del 5 % del tamaño de los datos originales, manteniendo más del 90 % de recall top-3 en menos de dos segundos en sus evaluaciones.
Ese matiz es importante porque ayuda a separar el entusiasmo viral de lo que realmente está demostrado. El repositorio habla de “97 % menos almacenamiento sin pérdida de precisión”, pero el paper académico lo formula de manera algo más prudente: habla de mantener una calidad de búsqueda comparable y de superar ciertos niveles de recall en benchmarks concretos. Es decir, la tesis central parece sólida, pero conviene no convertir una mejora muy fuerte en una promesa universal idéntica para cualquier carga de trabajo, cualquier modelo de embedding y cualquier tipo de documento.
Por qué LEANN importa de verdad
La relevancia de LEANN no está solo en la compresión. Lo que hace interesante al proyecto es que baja el umbral de entrada para ejecutar sistemas de búsqueda semántica local sobre datos personales o corporativos. El propio repositorio plantea casos de uso muy concretos: documentos PDF, Markdown y texto plano, historial de Apple Mail, Chrome, WeChat, ChatGPT, Claude, iMessage, Slack vía MCP, Twitter y hasta bases de conocimiento externas de gran tamaño. También ofrece integración con Claude Code a través de un servidor MCP, presentándolo como un reemplazo semántico para búsquedas mucho más básicas basadas en palabras clave.
Desde esa perspectiva, LEANN apunta a uno de los grandes debates del momento en IA: si el conocimiento personal y de equipo puede quedarse en el dispositivo en lugar de viajar continuamente a la nube. El repositorio insiste varias veces en esa idea, hablando de privacidad total, cero costes cloud y control completo del dato. Sin embargo, ahí también conviene introducir una precisión. LEANN sí puede ejecutarse de forma local y privada, especialmente si se combina con Ollama u otros backends locales, pero el propio proyecto también soporta proveedores externos como OpenAI, Anthropic y APIs compatibles. Por tanto, el “100 % privado” depende de cómo se configure el sistema y de qué backend de generación se use realmente.
Cómo reduce tanto el almacenamiento
La clave técnica de LEANN está en combinar varias técnicas. El paper y el repositorio destacan la recomputación selectiva basada en grafos, una poda que preserva nodos de alto grado, el uso de formatos compactos para la estructura del índice y una estrategia de búsqueda en dos niveles que intenta recomputar solo lo necesario en la ruta de recuperación. En lugar de pagar el coste permanente de guardar todos los vectores densos, LEANN traslada parte del trabajo al momento de la consulta. Eso reduce el espacio ocupado, aunque obviamente introduce un intercambio entre almacenamiento y cómputo.
En el fondo, LEANN no elimina el coste de los embeddings; lo redistribuye. Y esa es precisamente una de sus ideas más potentes. Para muchos entornos personales o edge, el gran problema no es tanto gastar algo más de CPU en el momento de buscar, sino tener que reservar cientos de gigabytes solo para mantener el índice vivo. Si ese coste se puede desplazar sin castigar demasiado la latencia ni la calidad, entonces el RAG local deja de ser una curiosidad técnica y empieza a parecer una opción práctica.
El proyecto también ofrece dos backends principales, HNSW como opción por defecto y DiskANN como alternativa orientada a mayor rendimiento, además de funciones como chunking con conocimiento de AST para código, filtros por metadatos, modo grep para búsqueda exacta y un CLI bastante completo para construir, buscar, preguntar, vigilar cambios y eliminar índices. Esa combinación hace que LEANN no se presente solo como un paper bonito, sino como una herramienta bastante orientada a uso real.
Entre la promesa viral y la realidad práctica
LEANN encaja muy bien en el clima actual del mercado: más IA local, más MCP, más búsqueda semántica sobre datos propios y menos dependencia obligatoria de infraestructuras pesadas. Su valor está en que ataca uno de los cuellos de botella menos glamourosos del RAG, que es el peso del índice. No promete el mejor modelo del mundo ni un agente espectacular; promete algo más prosaico y quizá más útil: hacer viable la búsqueda semántica a gran escala en equipos modestos.
La gran pregunta ahora es si ese ahorro tan agresivo se mantendrá igual de bien fuera de los benchmarks y en flujos de trabajo cotidianos, con datos desordenados, modelos distintos y usuarios menos técnicos. Pero incluso con esa cautela, LEANN ya ha lanzado un mensaje claro al sector: el futuro del RAG personal no depende solo de mejores modelos, sino también de índices mucho más ligeros. Y ahí es donde este repositorio empieza a destacar.
Preguntas frecuentes
¿Qué hace exactamente LEANN?
LEANN es un índice vectorial de bajo almacenamiento para búsquedas semánticas y RAG. En vez de guardar todos los embeddings como hacen muchas bases vectoriales tradicionales, usa una estructura de grafo compacta y recomputa parte de ellos bajo demanda durante la búsqueda.
¿Es cierto que reduce 201 GB a 6 GB?
Esa cifra aparece en la tabla comparativa del repositorio para un caso de 60 millones de fragmentos en un dataset tipo wiki. Es una cifra publicada por el proyecto y coherente con su mensaje general, aunque no debe interpretarse automáticamente como un resultado universal para cualquier despliegue.
¿LEANN funciona realmente sin nube y sin GPU?
Puede funcionar de forma local y el proyecto lo plantea para dispositivos personales, pero no toda la experiencia tiene por qué ser 100 % local si se configuran proveedores externos de embeddings o generación. Para máxima privacidad, el propio repositorio recomienda backends locales como Ollama.
¿Qué respaldo técnico tiene más allá del repositorio?
LEANN está respaldado por un paper académico publicado en arXiv y aceptado, según la web del autor, en MLSys 2026, con una versión corta previa en VecDB@ICML 2025.