
La mayoría de administradores de sistemas y desarrolladores que han jugado con agentes de IA se han topado con el mismo muro: cuando conectas el modelo a Slack, GitHub, Jira, el monitoring, el CRM y un par de bases de datos internas, el contexto explota, las llamadas a herramientas se vuelven frágiles y la latencia se dispara.
Anthropic acaba de anunciar en la Claude Developer Platform tres piezas pensadas precisamente para ese dolor de plataforma:
- Tool Search Tool: búsqueda dinámica de herramientas.
- Programmatic Tool Calling: orquestación de herramientas desde código, no solo con prompts.
- Tool Use Examples: ejemplos de uso reales embebidos en la definición de cada herramienta.
Junto con effort control y los mecanismos de compactación de contexto, la idea es clara: que Claude pueda comportarse como un agente de plataforma o SRE capaz de trabajar con decenas de servicios sin que cada sesión sea un festival de tokens y “hallucinated APIs”.
El problema real: demasiadas herramientas, poco contexto
En un entorno corporativo razonable es fácil acabar con:
- Un servidor MCP de GitHub con decenas de operaciones (issues, PRs, workflows, etc.).
- Conectores a Slack, Grafana, Sentry, Jenkins, Jira, ServiceNow…
- Algún que otro “toolset” interno para bases de datos, CMDB o sistemas de tickets.
Cada herramienta llega con su JSON Schema, descripciones, enums… y eso son miles de tokens antes de que el modelo lea la primera petición. Anthropic comenta casos internos donde solo las definiciones de herramientas se comían más de 70 k tokens de contexto incluso antes de empezar a trabajar.
Para un modelo que tiene que:
- Leer el historial de conversación.
- Entender el incidente o la tarea.
- Llamar a varias herramientas y razonar sobre los resultados…
…esa sobrecarga inicial es matar al agente antes de que arranque.
Tool Search Tool: catálogo de APIs bajo demanda
La solución de Anthropic pasa por tratar las herramientas como si fueran un catálogo consultable. En lugar de cargar todas las definiciones en cada petición, se define una única herramienta de búsqueda (por ejemplo, basada en regex o BM25) y el resto se marcan con defer_loading: true.
La secuencia típica sería:
- Le pasas al API todas tus herramientas MCP o propias, pero muchas de ellas “diferidas”.
- Claude solo ve desde el principio:
- La Tool Search Tool.
- Un puñado de herramientas críticas marcadas como
defer_loading: false(las que usas a diario).
- Cuando necesita hacer algo concreto (ej. “crear un PR en GitHub” o “buscar logs de un pod en producción”), primero busca.
- La Tool Search Tool devuelve las herramientas relevantes, que en ese momento sí se expanden con sus definiciones completas en el contexto.
Ventajas para un equipo de plataforma:
- Contexto más limpio: pasas de decenas de miles de tokens en definiciones a unos pocos miles de las herramientas realmente usadas en esa tarea.
- Menos errores de selección: en lugar de elegir a ciegas entre 15 métodos “create_something”, Claude busca por descripción y contexto.
- Mejor caching de prompts: como las herramientas diferidas no forman parte del prompt inicial, el sistema puede aprovechar mejor el caché de prompts.
La recomendación práctica:
Mantener siempre cargadas 3–5 herramientas “core” (por ejemplo, búsqueda en repos, lectura de tickets y consulta de métricas) y diferir el resto: operaciones de administración, herramientas muy específicas o integraciones poco frecuentes.
Programmatic Tool Calling: orquestación en Python en vez de “prompt spaghetti”
El siguiente cuello de botella aparece cuando el agente tiene que encadenar muchas llamadas o procesar grandes volúmenes de datos.
Ejemplos muy de sysadmin:
- Recorrer todos los servicios de Kubernetes, consultar métricas de error y generar un informe.
- Revisar gastos de infraestructura por proyecto y compararlos con presupuestos.
- Buscar patrones en miles de líneas de logs antes de proponer una causa raíz.
Si cada paso implica:
- Una llamada a herramienta.
- Una respuesta enorme inyectada al contexto.
- Una nueva inferencia del modelo para decidir el siguiente paso.
…la latencia y el consumo de tokens se disparan. Además, la lógica de control de flujo (bucles, reintentos, filtros) queda implícita en el prompt, lo que la vuelve frágil.
Con Programmatic Tool Calling, Claude pasa a escribir código de orquestación, normalmente en Python, que se ejecuta en la herramienta de code_execution. Ese código puede llamar a tus herramientas tantas veces como haga falta, procesar los resultados, agrupar y filtrar datos, y devolver al modelo solo el resultado final o un resumen.
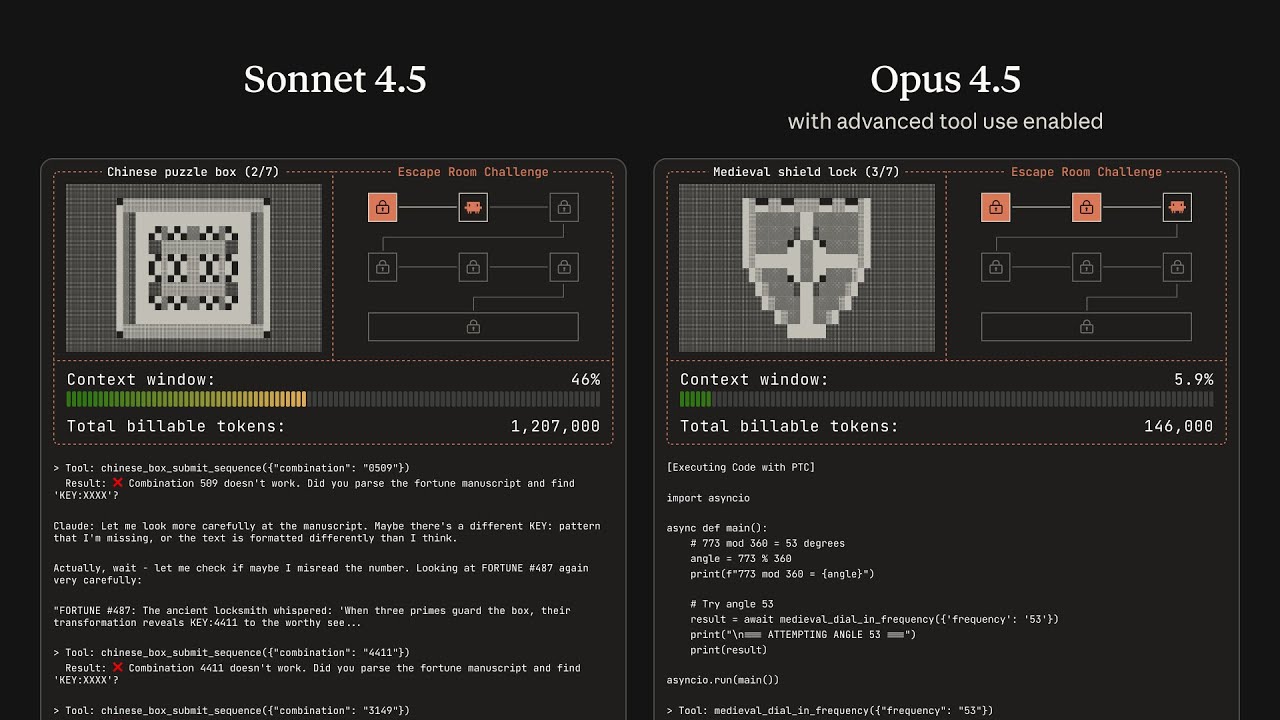
Ejemplo mental: “¿Quién se ha pasado del presupuesto de cloud?”
Supongamos que tienes tres herramientas:
get_projects()→ lista de proyectos con su owner.get_cloud_costs(project, month)→ desglose de costes por proyecto.get_budget(project)→ presupuesto asignado.
Con el enfoque clásico, el modelo pediría:
- Lista de proyectos (entra al contexto).
- Costes de cada proyecto, uno a uno (todas las respuestas al contexto).
- Presupuesto de cada proyecto.
- Haría las sumas y comparaciones “leyendo” el contexto.
Con Programmatic Tool Calling:
- Claude escribe un script que:
- Llama a
get_projects(). - Lanza en paralelo
get_cloud_costs()para todos. - Pide los presupuestos.
- Compara todo en memoria y construye una lista de “proyectos pasados de presupuesto”.
- Llama a
- Todo eso se ejecuta en la sandbox de código, fuera del contexto del modelo.
- Claude solo ve el resultado compacto: quizá una tabla con 5 proyectos, sus costes y sus límites.
Según los datos que comparte Anthropic, esto reduce de forma significativa tanto el consumo de tokens como la latencia en flujos con muchas herramientas, además de disminuir errores de lógica.
Cuándo merece la pena
Tiene sentido activar Programmatic Tool Calling cuando:
- Hay 3 o más llamadas de herramienta encadenadas.
- Los resultados intermedios son grandes (logs, listados, métricas crudas).
- Se pueden ejecutar llamadas en paralelo sin riesgo (operaciones idempotentes).
- La lógica se parece más a un pequeño script o “runbook programable” que a una única pregunta.
Para una simple consulta de “dame el estado de este servicio”, la llamada clásica sigue siendo suficiente.
Tool Use Examples: menos 400, más ejemplos reales
Queda un tercer problema, que cualquiera que haya intentado exponer APIs internas a un LLM conoce bien: el JSON es válido, pero el uso no.
Un esquema puede decir que un campo es un string, pero no:
- Qué formato de fecha espera.
- Cómo deben ir los IDs.
- Qué campos opcionales se suelen usar juntos.
- Qué combinaciones representan un “incidente crítico” frente a una simple tarea.
Con Tool Use Examples, cada herramienta puede incluir varios ejemplos reales de input. No se trata de documentación separada, sino de ejemplos embebidos en la propia definición de la herramienta.
Por ejemplo, para un endpoint de creación de incidentes podrías incluir:
- Un incidente crítico de producción con todos los campos (servicio, severidad, etiquetas, escalado, SLA…) bien rellenados.
- Una petición de mejora con prioridad baja y poca información.
- Una tarea interna casi vacía, solo con título.
Claude aprende así:
- Qué formato de fecha usas (ISO simple, con zona horaria, etc.).
- Cómo se forman los identificadores internos.
- Cuándo conviene proporcionar datos de contacto, SLA o etiquetas adicionales.
- Qué valores de prioridad suelen ir asociados a qué tipo de incidentes.
En las pruebas internas de Anthropic, este enfoque mejora notablemente la tasa de llamadas a herramientas con parámetros correctos, sobre todo en APIs complejas y con muchos campos opcionales.
Qué pueden hacer con esto equipos de plataforma y desarrollo
Para un medio orientado a administradores de sistemas y desarrolladores, el mensaje práctico es claro: los agentes dejan de ser juguetes de demo y se acercan al terreno de las plataformas internas.
Algunos escenarios interesantes:
- Copilotos de SRE que:
- Buscan métricas, logs y trazas en distintas herramientas de observabilidad.
- Ejecutan comprobaciones de salud en paralelo y resumen resultados.
- Abren tickets, comentan en Slack y actualizan runbooks.
- Asistentes de DevOps/GitOps que:
- Analizan el estado de pipelines y despliegues.
- Proponen cambios en manifests, generan PRs y comentan impactos.
- Orquestan operaciones repetitivas con Programmatic Tool Calling sin llenar el contexto.
- Agentes de soporte interno que:
- Consultan múltiples sistemas (CMDB, inventario de máquinas, directorio de usuarios).
- Aplican reglas de negocio complejas en código.
- Devuelven respuestas resumidas al usuario final o al técnico de soporte.
En todos los casos, los tres componentes juegan roles distintos:
- Tool Search Tool → descubrimiento eficiente en catálogos grandes.
- Programmatic Tool Calling → ejecución y orquestación eficientes.
- Tool Use Examples → invocaciones precisas de APIs internas.
La promesa de Anthropic es que, combinando estas piezas, Claude pueda funcionar como una capa de automatización más en el stack de la empresa, al nivel de Terraform, Ansible o los pipelines de CI/CD, pero impulsada por lenguaje natural.
Para los equipos de plataforma que ya están experimentando con MCP o integraciones directas, estas novedades pueden ser el paso que faltaba para pasar del laboratorio al entorno real.
Fuente: Noticias inteligencia artificial








