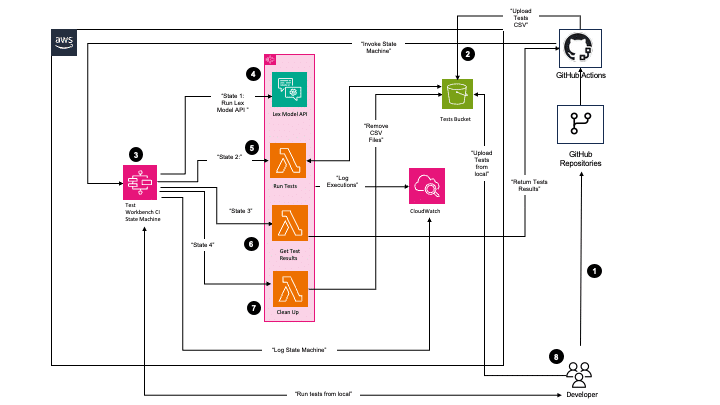
Cuando AWS US-EAST-1 estornuda: manual técnico para limitar el “blast radius”, operar durante la caída y diseñar según tu RTO/RPO
La última degradación a gran escala en AWS US-EAST-1 (N. Virginia) volvió a dejar claro que un fallo regional puede convertirse en un problema global: aumentos de latencia y errores en servicios base derivaron en inicios de sesión inestables, subidas bloqueadas, APIs que respondían a tirones y 5xx intermitentes en apps de consumo y SaaS corporativos. Esto no va de